What are the language identifier codes for Kurdish language?
Fri, 27/08/2010 – 16:39 — Admin
Language codes are those that assigns letters and/or numbers as identifiers for languages. These codes are often used to organise library collections, to choose the correct localizations and translations in computerising the literature, and finally, a shorthand designation for forms.
There are a wide variety of processes for which it is necessary to identify the specific language in advance. Language-based indexing and searching are fairly obvious examples from the realm of bibliographic applications, as is in semantic interpretation. But there are a number of others: spell-checking, sorting, syllabification and hyphenation, morphological and syntactic parsing, fuzzy string searches and comparisons, speech recognition, speech synthesis, semantic associations, thesaurus look-ups, and potentially many others.
The international registration authorities ISO 639 is the set of international standards that lists short codes for the representation of names of languages. It was also the name of the original standard, approved in 1967 and withdrawn in 2002. The original ISO 639 has been replaced by ISO 639-1 which contains two character codes, ISO 639-2 and ISO 639-3 which are counting three charechter codes for the most languages of the world.
The ISO 639-1 code set was devised for use in terminology, lexicography and linguistics.
The ISO 639-2 code set was devised for use by libraries, information services, and publishers to indicate language in the exchange of information, especially in computerized systems. The codes have been widely used in the library community and may also be adopted for any application requiring the expression of language in coded form by terminologists and lexicographers.
The ISO 639-3 code set was devised for broad use in a variety of applications where more specific language coding was necessary than the other two standards provided.
For bibliographic and linguistic classifications, Kurdish language is identified by these international standards as:
KU (ISO 639-1) , two first letters of the word Kurdish
KUR (ISO 639-2, ISO 639-3), three first letters of the word Kurdish
In 1999 the KURDTISTNICA Network used the Kurdish linguistic and bibliographic identifying code to apply for the first Kurdish top domain (.KU) based on Cultural and linguistic bases. These were presented for consideration and adoption to two Kurdish administrations at the time and the Kurdish Parliament, as well the top-domain registration’s authorities.
There are also three character identifiers for major dialects of Kurdish. Unfortunately lack of understanding of Kurdish language native divisions has led to misrepresenting the sub-dialects under irrelevant abbreviations. KAL has formally put forward a complain to SIL International reconsideration in correcting the sub-dialect identifiers of Kurdish language. The ISO 639-3 is under review and restructuring. KAL is suggesting the use of following three character codes which fully represents the position of of Kurdish sub-dialects in Kurdish Genealogy language tree as:
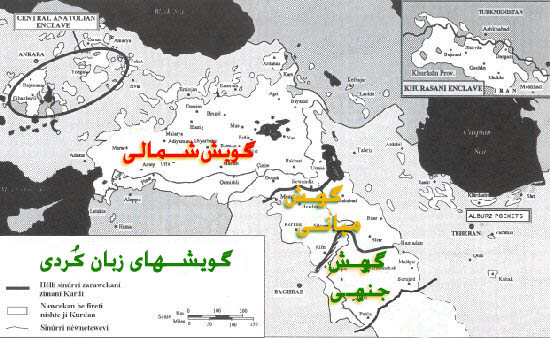
NKU – North Kurdish (Kurmanjí) branch and its sub-dialect
CKU – Central/Mid Kurdish (Soraní) branch and its sub-dialect
SKU – South Kurdish (Pehlawaní) branch and its sub-dialect
DKU – Dimili Kurdish (Zaza) branch and its sub-dialect
HKU – Hawrami Kurdish branch and its sub-dialect
The SIL International argues that some of these sub-dialects do not belong to Kurdish language and they have been treated as separate independent languages. It is noteable that SIL International the registering authority for ISO 639-3 which is a faith-based nonprofit organisation committed to serving language communities worldwide as they build capacity for sustainable language development.
Sources:
SIL International
Library of Congress
International Information Centre for Terminology
Language Codes – Wikipedia
Login or register to post comments 13950 reads